

Today, organizations are constantly seeking ways to use advanced large language models (LLMs) for their specific needs. These organizations are engaging in both pre-training and fine-tuning massive LLMs, with parameter counts in the billions. This process aims to enhance model efficacy for a wide array of applications across diverse sectors, including healthcare, financial services, and marketing. However, customizing these larger models requires access to the latest and accelerated compute resources.
In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans, which can bring down your training cluster procurement wait time. A training plan provides simple and predictable access to accelerated compute resources (supporting P4d, P5, P5e, P5en, and trn2 as of the time of writing), allowing you to use this compute capacity to run model training on either Amazon SageMaker training jobs or SageMaker HyperPod.
We guide you through a step-by-step implementation on how you can use the (AWS CLI) or the AWS Management Console to find, review, and create optimal training plans for your specific compute and timeline needs. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters.
You can check out the launch of this new feature in Meet your training timelines and budget with new Amazon SageMaker HyperPod flexible training plans.
Business challenges
As organizations strive to harness the power of LLMs for competitive advantage, they face a significant hurdle: securing sufficient and reliable compute capacity for model training. The scale of these models demands cutting-edge accelerated compute hardware. However, the high cost and limited availability of such resources create a bottleneck for many businesses. This scarcity not only impacts timelines, but also stretches budgets, potentially delaying critical AI initiatives. As a result, organizations are seeking solutions that can provide consistent, scalable, and cost-effective access to high-performance computing resources, enabling them to train and fine-tune LLMs without compromising on speed or quality.
Solution overview
SageMaker HyperPod training plans, a new SageMaker capability, address this challenge by offering you a simple-to-use console UI or AWS CLI experience to search, review, create, and manage training plans.
Capacity provisioned through SageMaker training plans can be used with either SageMaker training jobs or SageMaker HyperPod. If you want to focus on model development rather than infrastructure management and prefer ease of use with a managed experience, SageMaker training jobs are an excellent choice. For organizations requiring granular control over training infrastructure and extensive customization options, SageMaker HyperPod is the ideal solution. To better understand these services and choose the one most appropriate for your use case, refer to Generative AI foundation model training on Amazon SageMaker, which provides detailed information about both options.
The following diagram provides an overview of the main steps involved in requesting capacity using SageMaker training plans for SageMaker training jobs.
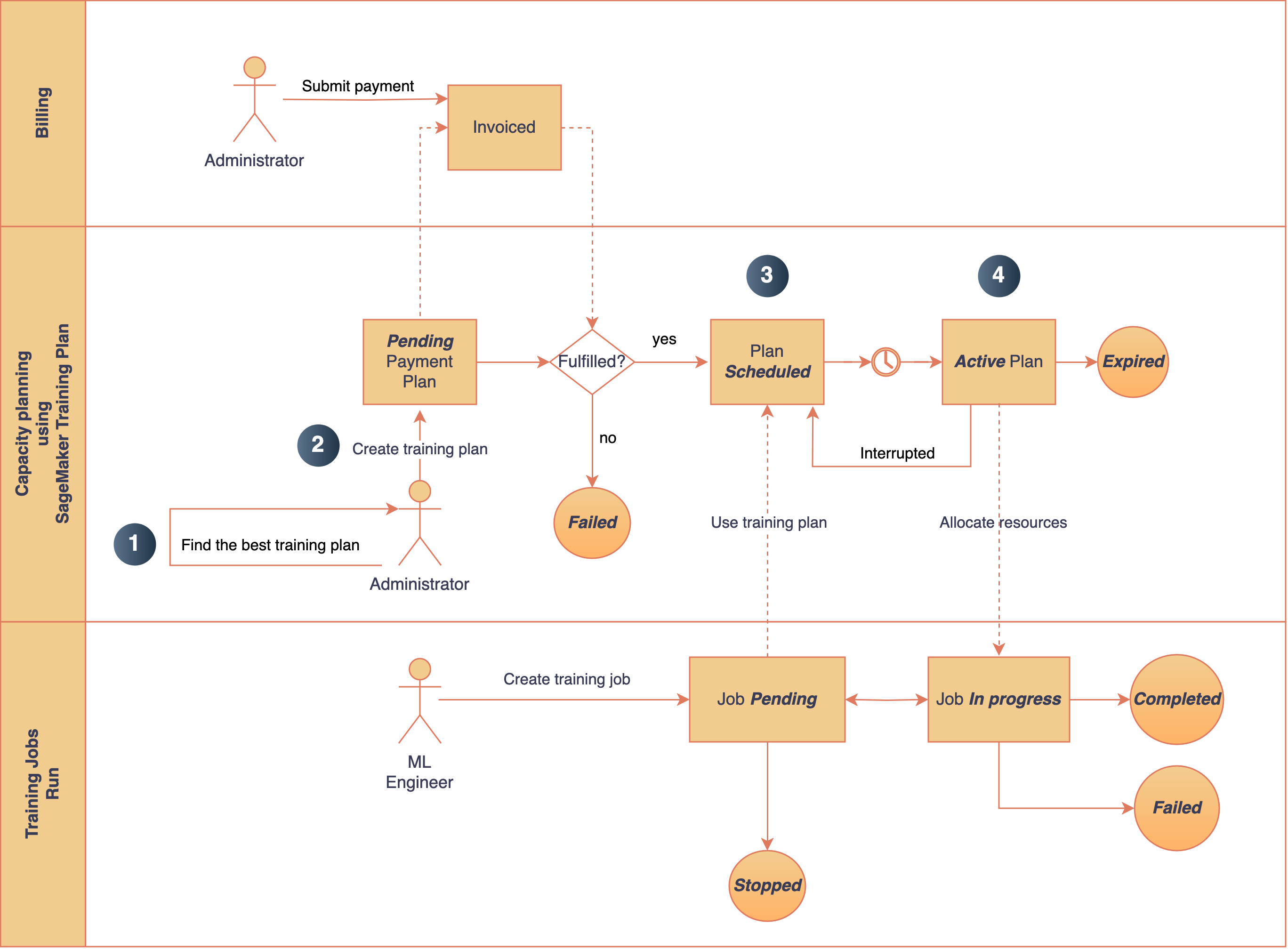
Figure 1: The main steps involved in procuring capacity via SageMaker HyperPod training plans. Note: This workflow arbitrarily uses SageMaker training jobs as the target; you may choose to use SageMaker HyperPod too.
At a high level, the steps to create a training plan are as follows:
- Search the training plans that best match your capacity requirements, such as instance type, instance count, start time, and duration. SageMaker finds the optimal plans across one or more segments.
- After reviewing the available training plan offerings, you can reserve the plan that meets your requirements.
- Schedule your SageMaker training jobs by using a training plan with a
training-jobtarget resource. Note, we are only usingtraining-jobfor illustration purposes. You may also usehyperpod-clusteras your target resource. - Describe and list your existing training plans. When the capacity is available, it will be allocated to the scheduled training job.
In the following sections, we shift our focus to the solution walkthrough associated with training plans.
Prerequisites
Complete the following prerequisite steps:
- If you’re using an AWS Identity and Access Management (IAM) user for this solution, make sure that your user has the
AmazonSageMakerFullAccesspolicy attached to it. To learn more about how to attach a policy to an IAM user, see Adding IAM identity permissions (console). - If you’re setting up the AWS CLI for the first time, follow the instructions at Getting started with the AWS CLI.
- If you choose to use the AWS CLI, make sure you are on the most up-to-date AWS CLI version.
Create a training plan
In this post, we discuss two ways to create a training plan: using the SageMaker console or the AWS CLI.
Create a SageMaker training plan using the SageMaker console
The SageMaker console user experience for creating a training plan is similar for both training jobs and SageMaker HyperPod. In this post, for demonstration purposes, we show how to create a training plan for a SageMaker HyperPod cluster.
- On the SageMaker console, choose Training plans in the navigation pane.
- Create a new training plan.
- For Target, select HyperPod cluster.
- Under Instance attributes, specify your instance type (ml.p5.48xlarge) and instance count (16).
- Under Date settings to search for an available plan, choose your preferred training date and duration (for example, 10 days).
- Choose Find training plan.
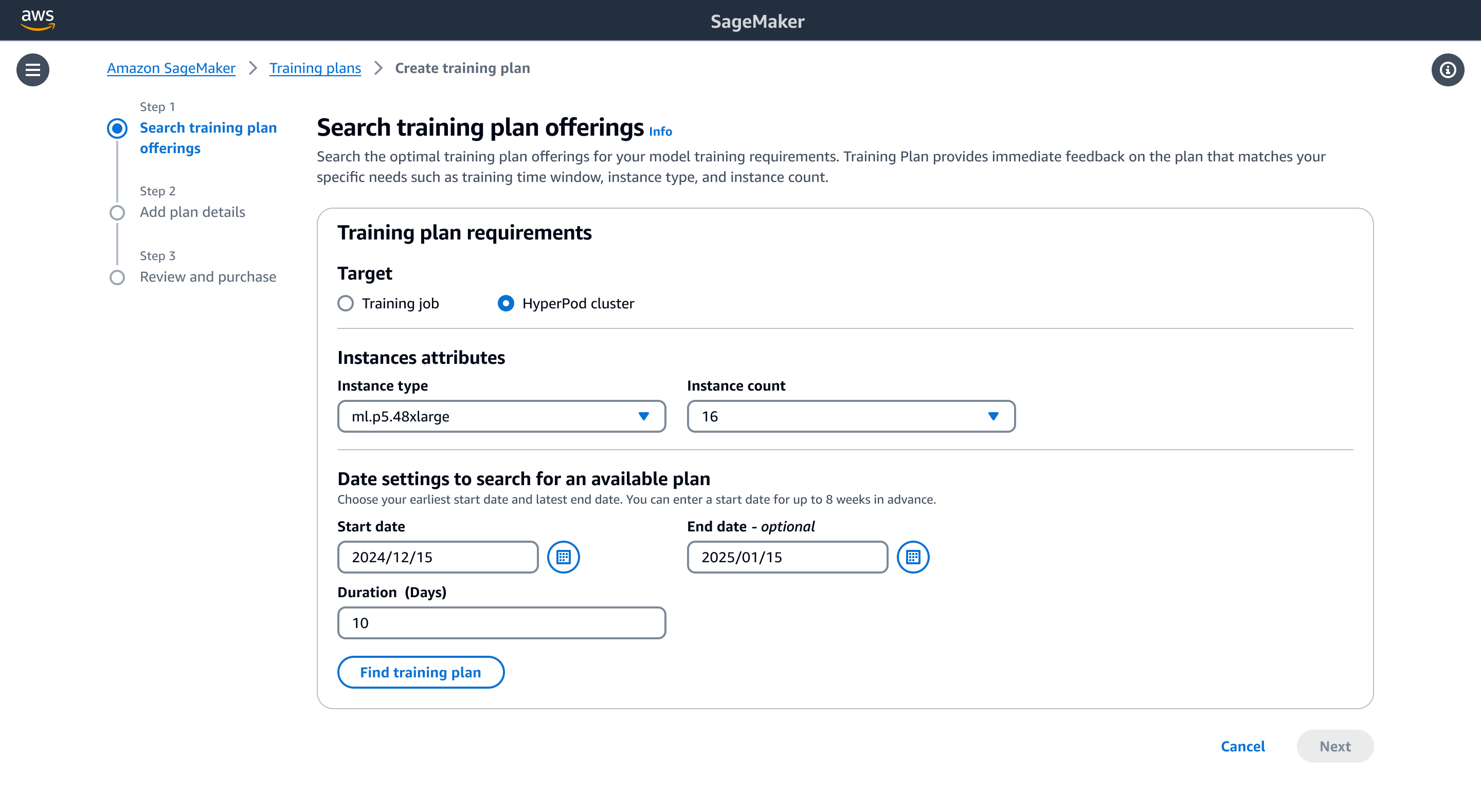
Figure 2: You can search for available training plan offerings via the SageMaker console! Choose your target, select your instance type and count, and specify duration.
SageMaker suggests a training plan that is split into two 5-day segments. This includes the total upfront price for the plan as well as the estimated data transfer cost based on the data location you provided.
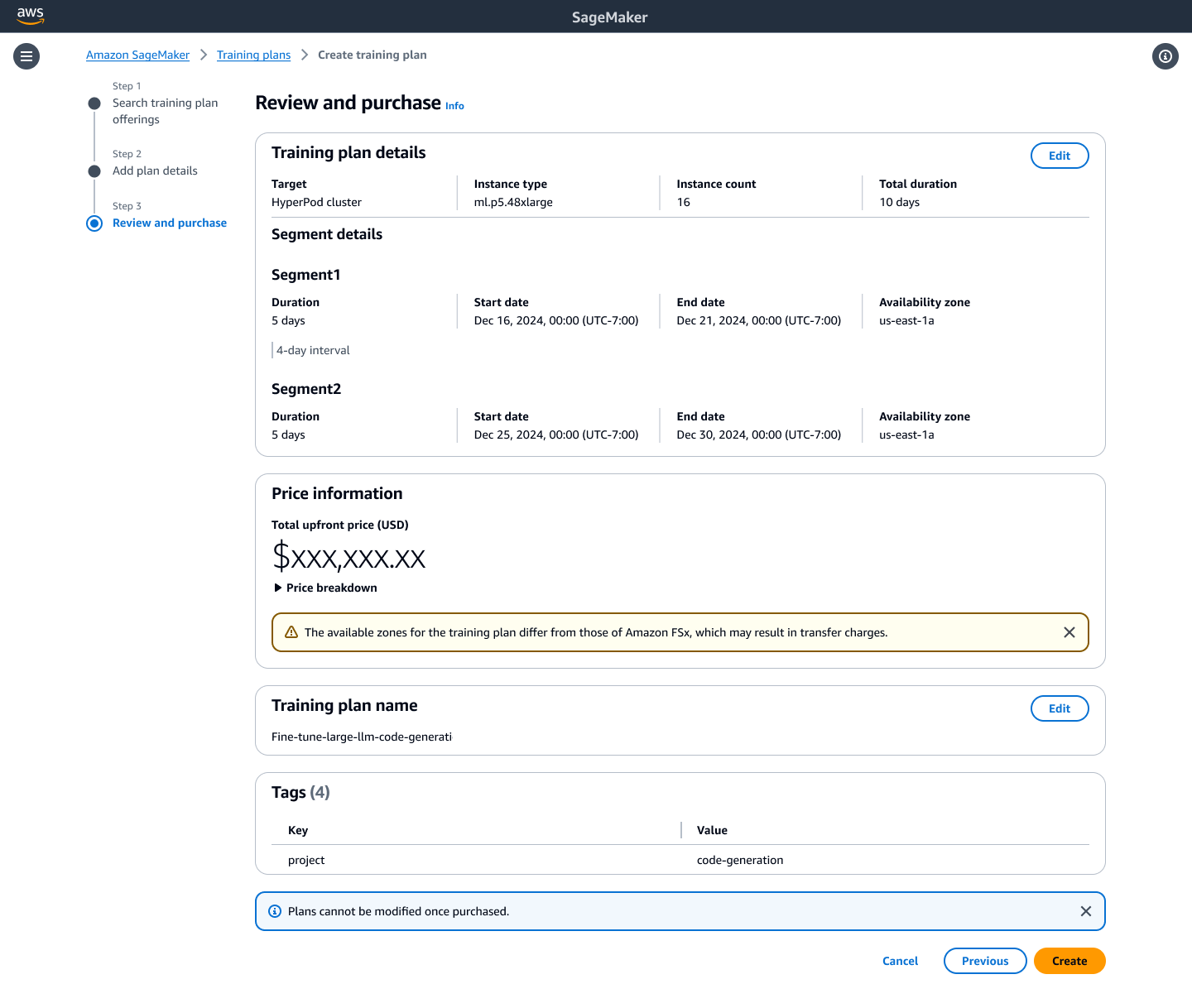
Figure 3: SageMaker suggests a training plan based on your inputs. In this example, SageMaker suggests a training plan split across two 5-day segments. You will also see the total upfront price.
- Review and purchase your plan.
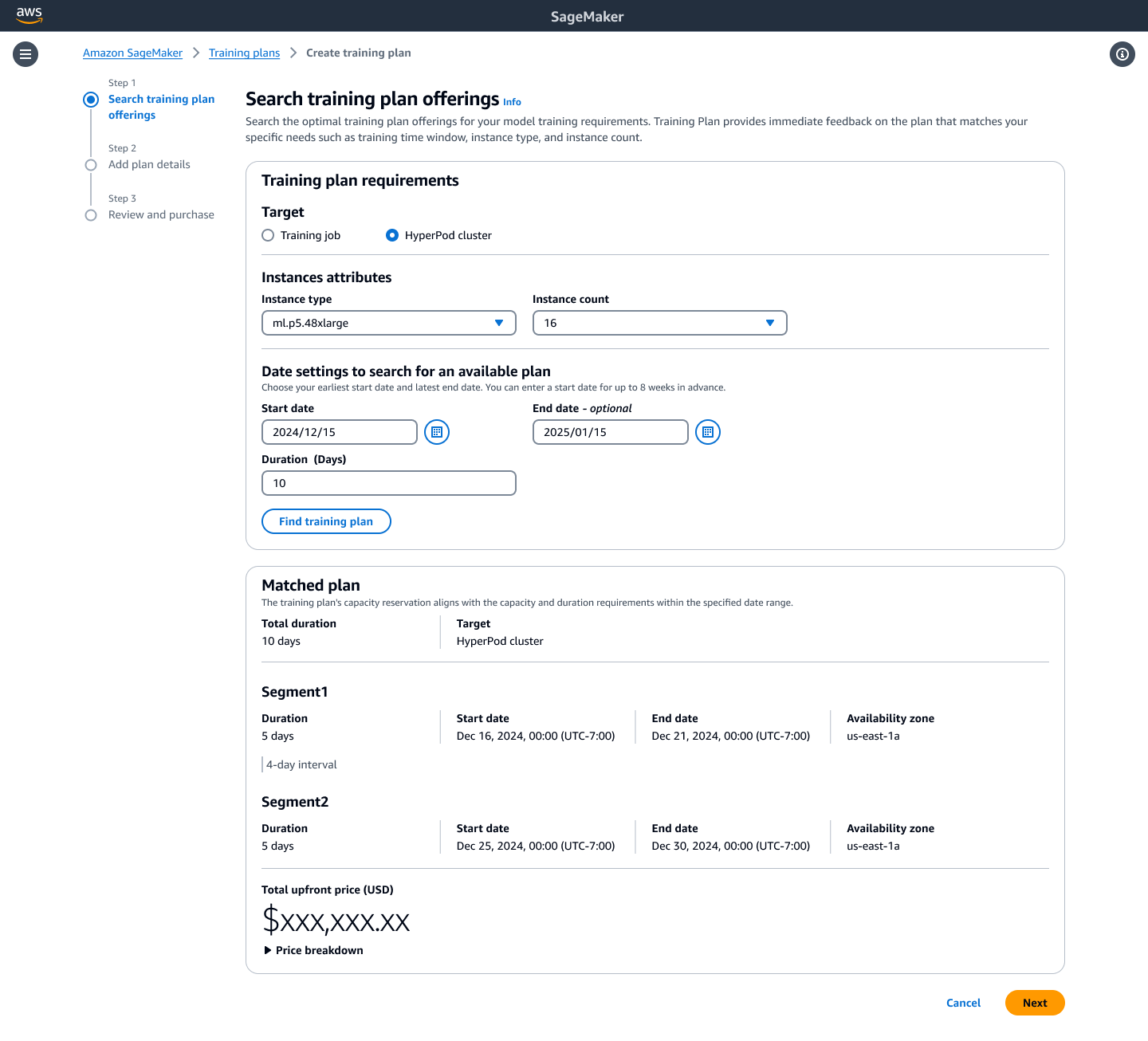
Figure 4: Once you’re happy with your selection, you can review and purchase your training plan!
After you create the training plan, you can see the list of training plans created. The plan initially enters a Pending state, awaiting payment. Once the payment is processed (unless the payment cycle has changed), the plan will transition to the Scheduled state. At this point, you can begin queuing jobs or creating clusters using the plan. On the plan’s start date, it becomes Active, and resources are allocated. Your training tasks can then start running (pending resource availability).
Make sure you pay for the training plan using the AWS Billing and Cost Management console for your plan to show up on your SageMaker console. You will receive an invoice to resolve before being able to proceed.
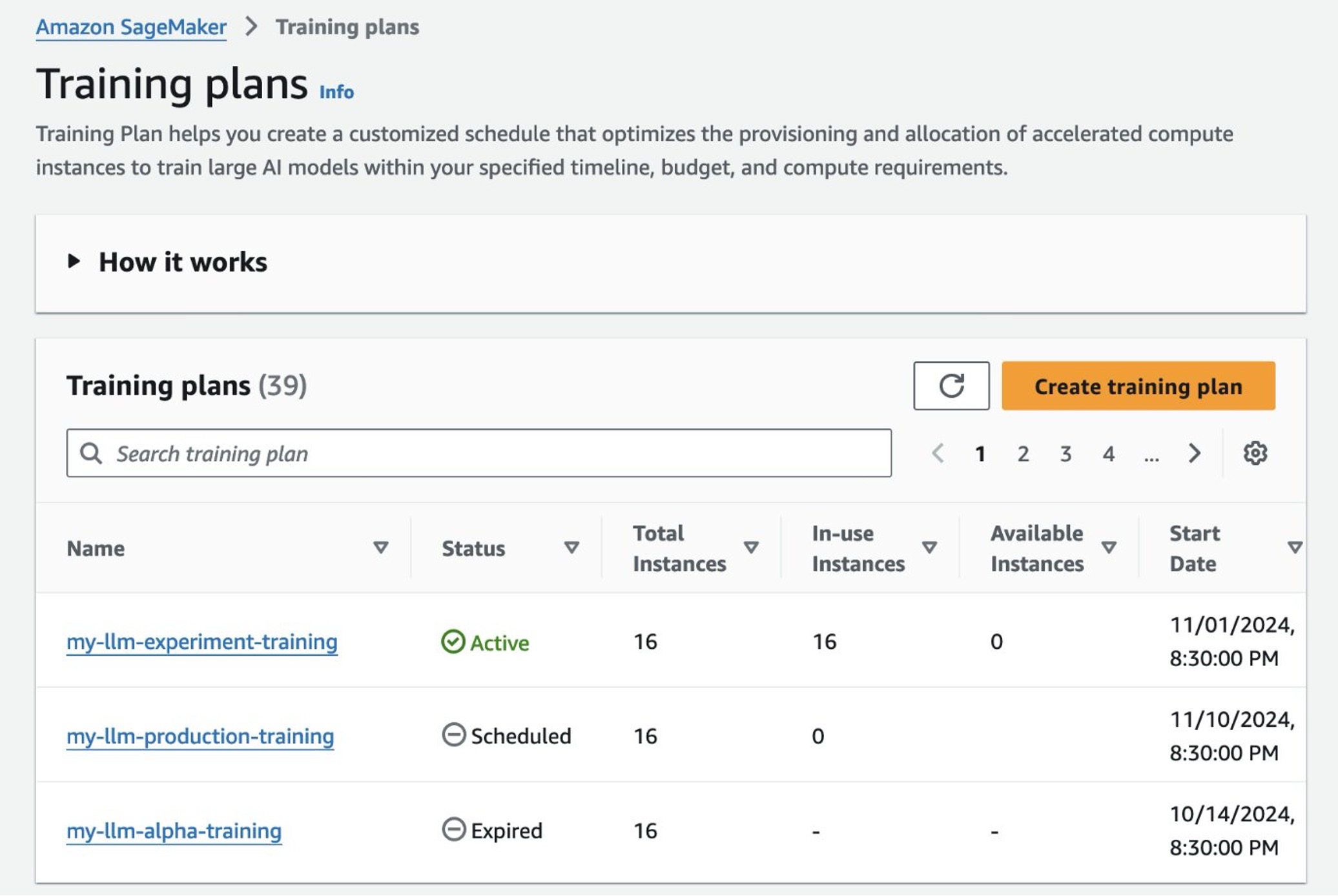
Figure 5: You can list out your training plans on the SageMaker console. You can start using your plan once it transitions to the Active state.
Create a SageMaker training plan using the AWS CLI
Complete the following steps to create a training plan using the AWS CLI:
- Start by calling the API, passing your capacity requirements as input parameters, to search for all matching training plan offerings.
The following example searches for training plan offerings suitable for two ml.p5.48xlarge instances for 96 hours in the us-west-2 region. In this example, we also have filters for what time frame we want to use the training plan, and we also filter for training plans that can be used for SageMaker HyperPod cluster workloads using the target-resources parameter:
Each TrainingPlanOffering returned in the response is identified by a unique TrainingPlanOfferingId. The first offering in the list represents the best match for your requirements. In this case, the SageMaker SearchTrainingPlanOfferings API returns a single available TrainingPlanOffering that matches the specified capacity requirements:
Make sure that your SageMaker HyperPod training job subnets are in the same Availability Zone as your training plan.
- After you choose the training plan that best suits your schedule and requirements, you can reserve it by calling the
CreateTrainingPlanAPI as follows:
You will see an output that looks like the following:
After you create the training plan, you will have to pay. Be on the lookout for an invoice. You can also find this on the AWS Billing and Cost Management console.
- You can list all the training plans that are created in your AWS account (and Region) by calling the
ListTrainingPlansAPI:
This will give you a summary of the training plans in your account. After you have your training plan (the newly created p5-training-plan), you can check its details using either the console or the DescribeTrainingPlan API as follows:
Use a training plan with SageMaker HyperPod
When your training plan status transitions to Scheduled, you can use it for new instance groups in either a new or existing SageMaker HyperPod cluster. You can use both the CreateCluster and UpdateCluster APIs to create a new SageMaker HyperPod cluster with your training plan, or update an existing cluster respectively. You can also choose to directly use the SageMaker console.
For a given SageMaker HyperPod cluster, training plans are attached at the instance group level, separately per each instance group. If desired, one SageMaker HyperPod cluster can have one or more training plans attached to multiple instance groups. You always have the option to omit a training plan and instead continue using On-Demand capacity as previously for other combinations of instance groups. However, you can’t mix training plan capacity with On-Demand capacity within the same instance group. You can also choose to have a partial cluster launch for every instance group. This means that even if all the requested capacity isn’t available, you can still spin up a cluster with capacity already available to you.
When a training plan is active, this is the time window when the TrainingPlanOfferings within it are scheduled to start and stop. Each time a TrainingPlanOffering starts, instance groups will automatically scale up to the specified count, and the instance group TrainingPlanStatus will reflect as Active. When a TrainingPlanOffering is scheduled to stop, your cluster’s instance groups will automatically scale down to zero, and the instance group TrainingPlanStatus will reflect as Expired.
Use a training plan with SageMaker HyperPod on the console
You can choose to either create a new cluster and create an instance group, or edit an existing cluster and edit an existing instance group. In the configuration, choose the same instance type that was chosen for a training plan and specify the desired instance count. The Instance capacity option will appear only when you choose an instance type that is supported for training plans. Choose the dropdown menu to scroll through valid training plans. The available training plan selections are listed by name and are filtered for only those that match the chosen instance type, that have at least the specified instance count, that were created with hyperpod-cluster as the target resource, and currently have a status of Scheduled or Active. Double-check these conditions if you don’t see an expected training plan name, and make sure that the expected training plan was created in the same account and in the same Region. The default selection is to use no training plan. Repeat the process for each instance group that should have a training plan.
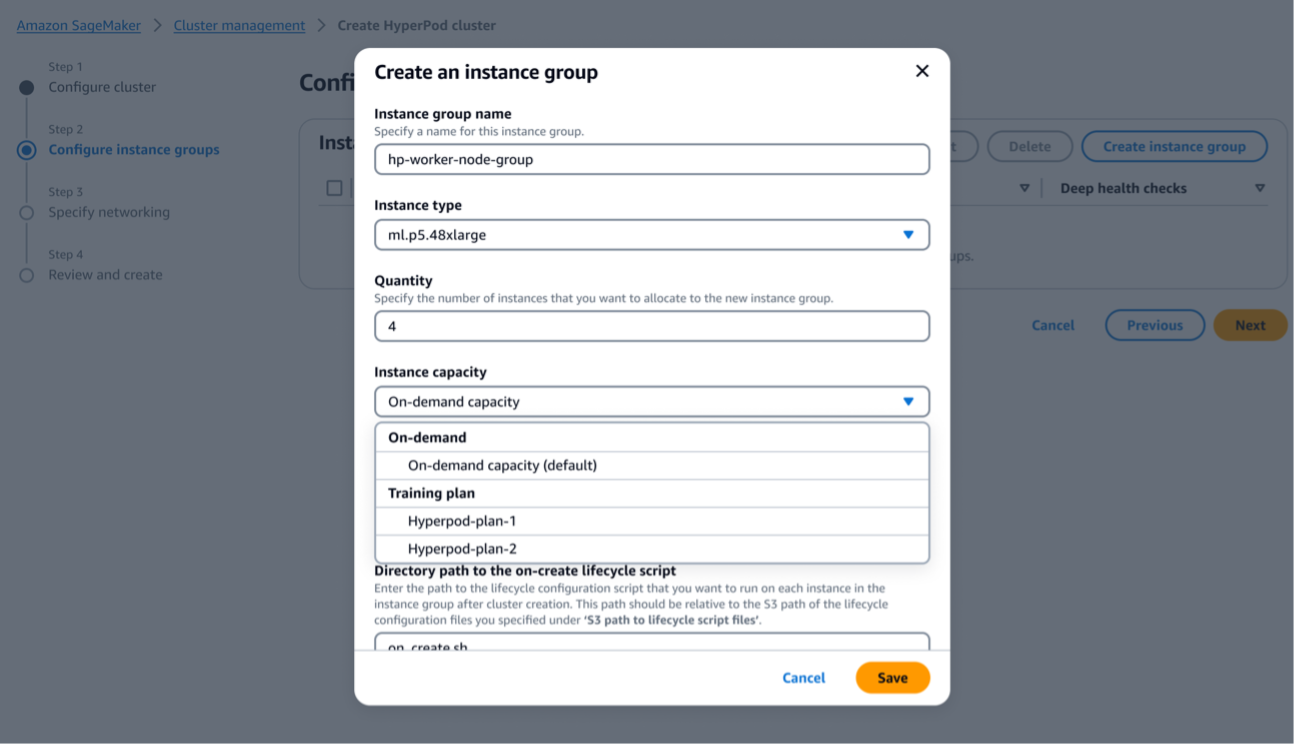
Figure 6: You can create an instance group for a SageMaker HyperPod cluster with the instances in your training plan. Make sure to choose the right training plan listed under “Instance capacity”
Use a training plan with SageMaker HyperPod with the AWS CLI
Complete the following steps to use your training plan with the AWS CLI:
- Create a SageMaker HyperPod cluster from scratch. For instructions, refer to the Amazon SageMaker HyperPod workshop or the Amazon EKS Support in Amazon SageMaker HyperPod workshop.
The following cluster configuration file defines a SageMaker HyperPod SLURM cluster named ml-cluster. The steps for using training plans will be the same, regardless of if you choose SLURM or Amazon Elastic Kubernetes Service (Amazon EKS) as the orchestrator. This cluster contains an instance group named controller-machine with 1 ml.m5.12xlarge instance as the head node of a SLURM cluster, and it will not use a training plan for the controller-machine instance group. We also define a worker instance group named worker-group-1 that specifies 2 ml.p5.48xlarge instances, which will be sourced from your training plan. Note the line "TrainingPlanArn"—this is where you specify your training plan by the full Amazon Resource Name (ARN). If you followed the steps in the prior sections, this should be the value of the environment variable TRAINING_PLAN_ARN. The following cluster configuration also skips some configuration parameters, such as VPCConfig and InstanceStorageConfig. Refer to the workshop or the following script for a complete SageMaker HyperPod cluster configuration file.
You can then create the cluster using the following code:
These next steps assume that you already have a SageMaker HyperPod cluster created. This section is relevant if you’d like to add an instance group that uses your training plan reserved instances to your existing cluster.
- To update an existing cluster, you can define another file called
update-cluster-config.jsonas follows. If you followed the instructions in the workshop to provision the cluster, you can use the providedcreate_config.shto get the values for yourenv_varsbefore sourcing them.
In this file, we define an additional worker group named worker-group-2 consisting of 2 ml.p5.48xlarge instances. Again, notice the line “TrainingPlanArn”—this is where you specify your training plan by the full ARN.
Make sure that you also update provisioning_parameters.json, and upload the updated file to your S3 bucket for SageMaker to use while provisioning the new worker group:
- Because this file is uploaded to Amazon Simple Storage Service (Amazon S3) for SageMaker to use while provisioning your cluster, you need to first copy that file over from Amazon S3:
aws s3 cp s3://${BUCKET}/src/provisioning_parameters.json provisioning_parameters.json
- Assuming your existing cluster has a controller machine group and a worker group with an ml.g5.48xlarge, you can add the lines in bold to your existing yaml file:
This step adds in the new worker group that you just created, which consists of your 2 ml.p5.48xlarge nodes from your training plan.
- Now you can re-upload the updated
provisioning-parameters.jsonfile to Amazon S3:
- Now, with both
cluster-config.json(nowupdate-cluster-config.json) andprovisioning-parameters.jsonupdated, you can add the training plan nodes to the cluster:
Use a training plan with a SageMaker training job
SageMaker training jobs offer two primary methods for execution: an AWS CLI command and the Python SDK. The AWS CLI approach provides direct control and is ideal for scripting, allowing you to create training jobs with a single command. The Python SDK offers a more programmatic interface, enabling seamless integration with existing Python workflows and using the high-level features in SageMaker. In this section, we look at how you can use a training plan with both options.
Run a training job on a training plan using the AWS CLI
The following example demonstrates how to create a SageMaker training job and associate it with a provided training plan using the CapacityScheduleConfig attribute in the create-training-job AWS CLI command:
After creating the training job, you can verify that it was properly assigned to the training plan by calling the DescribeTrainingJob API:
Run a training job on a training plan using the SageMaker Python SDK
The following example demonstrates how to create a SageMaker training job using the SageMaker Python SDK’s Training estimator. It also shows how to associate the job with a provided training plan by using the capacity_schedules attribute in the estimator object when using the SageMaker Python SDK.
For more information on the SageMaker estimator, see Use a SageMaker estimator to run a training job.
Make sure the SageMaker Python SDK version is updated to the latest version.
After creating the training job, you can verify that it was properly assigned to the training plan by calling the DescribeTrainingJob API:
Clean up
To clean up your resources to avoid incurring more charges, complete the following steps:
- Delete the SageMaker HyperPod cluster and associated resources such as storage, VPC, and IAM roles.
- If using SLURM, refer to Cleanup.
- If using Amazon EKS, refer to Cleanup.
- Delete any S3 buckets created.
- Make sure that the training plan created is used and completes the fulfillment lifecycle.
Conclusion
SageMaker training plans represent a significant leap forward in addressing the compute capacity challenges faced by organizations working with LLMs. By providing quick access to high-performance GPU resources, it streamlines the process of model training and fine-tuning. This solution not only reduces wait times for cluster provisioning, but also offers flexibility in choosing between SageMaker training jobs and SageMaker HyperPod, catering to diverse organizational needs. Ultimately, SageMaker training plans empower businesses to overcome resource constraints and accelerate their AI initiatives, leading to more efficient and effective usage of advanced language models across various industries.
To get started with a SageMaker training plan and explore its capabilities for your specific LLM training needs, refer to Reserve capacity with training plans and try out the step-by-step implementation guide provided in this post.
Special thanks to Fei Ge, Oscar Hsu, Takuma Yoshitani, and Yiting Li for their support in the launch of this post.
About the Authors
 Aman Shanbhag is an Associate Specialist Solutions Architect on the ML Frameworks team at Amazon Web Services, where he helps customers and partners with deploying ML Training and Inference solutions at scale. Before joining AWS, Aman graduated from Rice University with degrees in Computer Science, Mathematics, and Entrepreneurship.
Aman Shanbhag is an Associate Specialist Solutions Architect on the ML Frameworks team at Amazon Web Services, where he helps customers and partners with deploying ML Training and Inference solutions at scale. Before joining AWS, Aman graduated from Rice University with degrees in Computer Science, Mathematics, and Entrepreneurship.
 Kanwaljit Khurmi is an AI/ML Principal Solutions Architect at Amazon Web Services. He works with AWS product teams, engineering, and customers to provide guidance and technical assistance for improving the value of their hybrid ML solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
Kanwaljit Khurmi is an AI/ML Principal Solutions Architect at Amazon Web Services. He works with AWS product teams, engineering, and customers to provide guidance and technical assistance for improving the value of their hybrid ML solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
 Sean Smith is a Sr Specialist Solution Architect at AWS for HPC and generative AI. Prior to that, Sean worked as a Software Engineer on AWS Batch and CfnCluster, becoming the first engineer on the team that created AWS ParallelCluster.
Sean Smith is a Sr Specialist Solution Architect at AWS for HPC and generative AI. Prior to that, Sean worked as a Software Engineer on AWS Batch and CfnCluster, becoming the first engineer on the team that created AWS ParallelCluster.
 Ty Bergstrom is a Software Engineer at Amazon Web Services. He works on the Hyperpod Clusters platform for Amazon SageMaker.
Ty Bergstrom is a Software Engineer at Amazon Web Services. He works on the Hyperpod Clusters platform for Amazon SageMaker.