

Today, we are announcing the availability of Llama 3.2 on Amazon SageMaker JumpStart and Amazon Bedrock. Llama 3.2 models are a collection of state-of-the-art pre-trained and fine-tuned generative AI models. They are available in a range of sizes, from lightweight text-only 1B and 3B parameter models suitable for edge devices, to small and medium sized 11B and 90B parameter models capable of advanced inference tasks including multimodal support for high-resolution images. SageMaker JumpStart is a machine learning (ML) hub that provides access to algorithms, models, and ML solutions to help you get started with ML quickly. Amazon Bedrock is a fully managed service that offers a choice of high-performance foundation models (FMs) from leading AI companies such as Meta in a single API. It also provides a wide range of capabilities required to build generative AI applications with security, privacy, and responsible AI.
In this post, we demonstrate how to use the Llama 3.2 11B and 90B models for a variety of vision-based use cases. This is the first time that Meta’s Llama models have been released with vision capabilities. These new capabilities broaden the usability of the Llama models beyond traditional text-only applications. The vision-based use cases we cover in this post include answering visual questions of documents, extracting structured entity information from images, and image captioning.
Llama 3.2 11B and 90B Vision Model Overview
The Llama 3.2 multimodal and multilingual large language model (LLM) collection is a collection of pre-trained, instruction-tuned generative models of various sizes. The 11B and 90B models are multimodal and support text input/text output, and text+image input/text output.
Llama 3.2 11B and 90B are the first Llama models to support vision tasks, with a new model architecture that integrates image encoder representations into the language model. The new models are designed to be more efficient for AI workloads, with reduced latency and improved performance making them suitable for a wide range of applications. All Llama 3.2 models support 128,000 context length and maintain the expanded token capacity introduced in Llama 3.1. Additionally, the models offer improved multilingual support for eight languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
Llama 3.2 models are available today for inference on SageMaker JumpStart and Amazon Bedrock. With SageMaker JumpStart, you can initially access Llama 3.2 models in the US East (Ohio) AWS Region and support the instance types you require. Llama 3.2 90B and 11B models on Meta are also available on Amazon Bedrock in the US West (Oregon) Region and via cross-region inference in the US East (Ohio, N. Virginia) Region. Llama 3.2 1B and 3B models are available via cross-region inference in the US West (Oregon) and EU (Frankfurt) Regions, and in the US East (Ohio, N. Virginia) and EU (Ireland, Paris) Regions. Expanded regional availability is planned for the future.
Solution overview
In the following sections, we explain how to configure the Llama 3.2 vision model for vision-based inference on Amazon Bedrock and Amazon SageMaker JumpStart, and also demonstrate the use cases of document question answering, entity extraction, and caption generation.
The examples in this post use the Llama 3.2 90B model unless otherwise noted. Fashion images are taken from the Fashion Product Images Dataset. Caption generation images are taken from the Human Preference Synthetic Dataset. Interior design and real estate images are taken from the Interior design dataset.
Prerequisites
To implement the steps outlined in this post, you’ll need the following prerequisites:
For information about how to configure Llama 3.2 model access for Amazon Bedrock, see the release post. For details about how to create a model endpoint with SageMaker JumpStart, see the release post.
Configuring Llama 3.2 for Vision-Based Inference on Amazon Bedrock
To set up a vision-based inference task using the Llama 3.2 model on Amazon Bedrock, use the following code snippet:
Amazon Bedrock is messages We provide the object as part of the Converse API, which means that (compared to SageMaker JumpStart) you don’t need to convert your images to base64.
You can read the image with the following code:
To create a message object, use the following code:
# Build messages For model input
Call the Amazon Bedrock Converse API as follows:
Configuring Llama 3.2 for Vision-Based Inference on SageMaker
You can use the following code snippet to set up a vision-based inference task with a Llama 3.2 vision model on a SageMaker endpoint (for information about setting up an inference endpoint, see Llama 3.2 on the SageMaker JumpStart blog):
SageMaker JumpStart deployments can also use the message API style. messages It takes an object as input (similar to Amazon Bedrock Converse API). First, you need to load the image in base64 format before sending the message via the message object.
I use the following code to read the image:
Create messages Create the object with the following code:
In the code above, prompt This is a question about model inference using images.
After creation messages You can send objects as payloads to a SageMaker endpoint.
Answers to documentation questions
In this section, we present some use cases for Document Question Answering. We focus on two use cases: the first is answering questions based on financial results slides that contain complex graphical information, and the second is solving a math problem by looking at an image.
Financial Results Presentation Slides Q&A
The Llama 3.2 vision model can reason and answer questions based on images containing complex information such as plots, graphs, and tables. Let’s use the Financial Analyst Assistant model to analyze slides containing different types of financial information and answer questions. Using the Amazon Q2 2024 Financial Results Conference Call Slides document, we’ll ask Llama 3.2 some questions based on this slide deck.
At the first prompt, “What are the trends in sales over the past 12 months?” Please see the next slide.
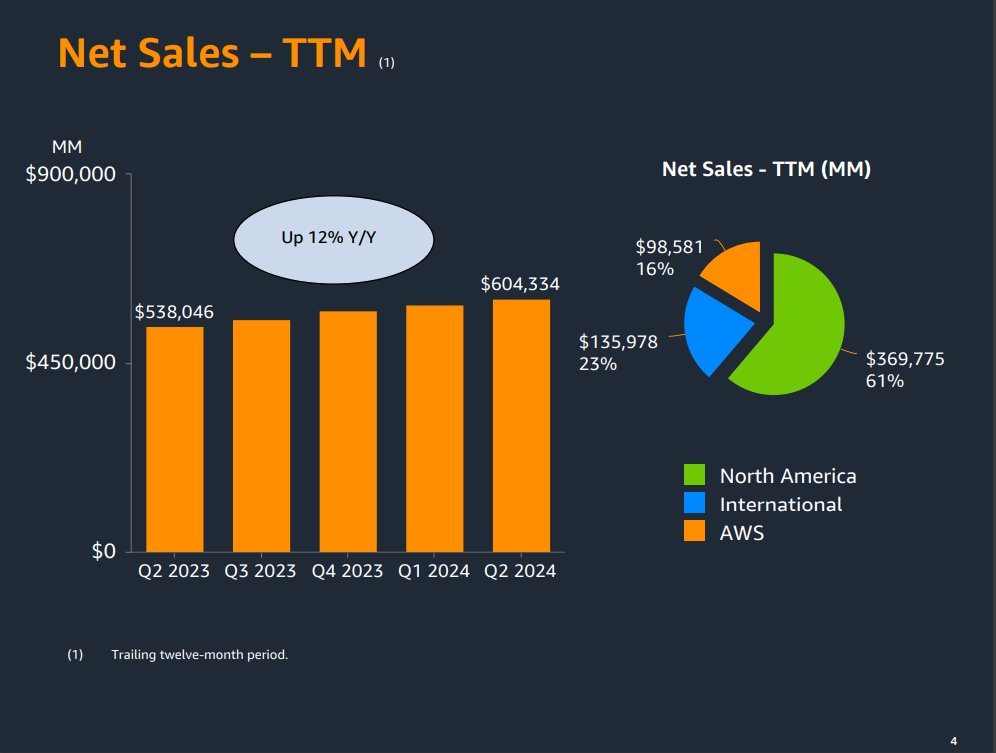
You will receive a response similar to the following:The sales are trending up 12% year over year. The bar graph shows that the sales have increased from $538,046 in Q2 2023 to $604,334 in Q1 2024, and further to $604,334 in Q2 2024. This indicates a steady growth in sales over the last twelve months.
next, “Can you help me understand this slide? What are the trends in operating cash flow and free cash flow over the past 12 months? What are the key contributors to the free cash flow trend?” Use the following slide:
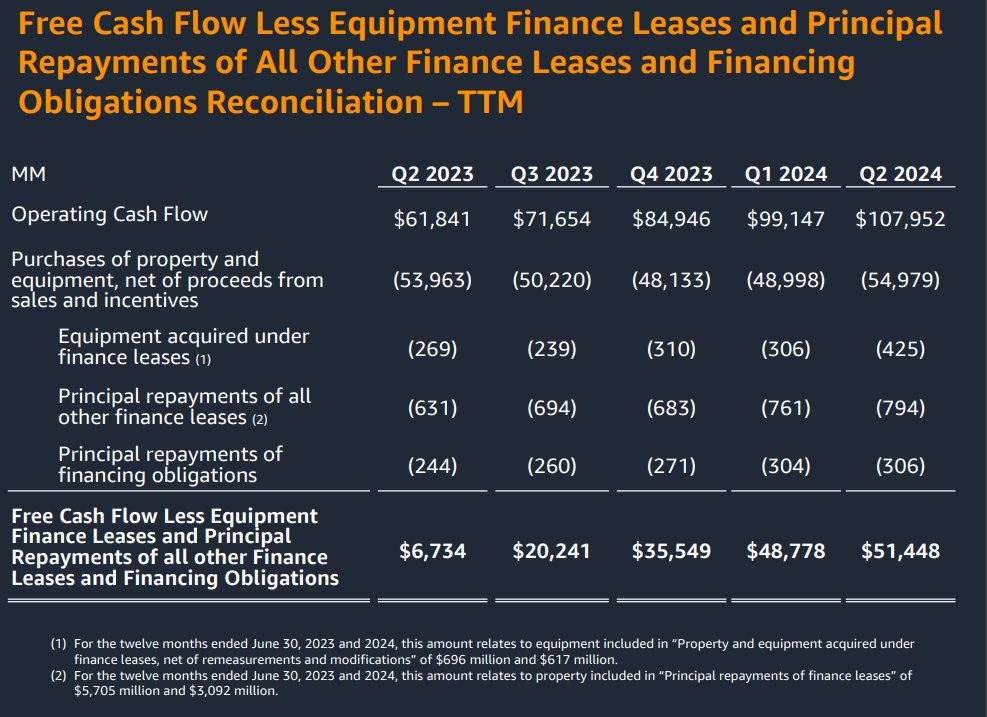
You will receive a response similar to the following:The slide presents a table with two main sections: "Operating Cash Flow" and "Free Cash Flow Less Equipment Finance Leases and Principal Repayments of All Other Finance Leases and Financing Obligations." The table is divided into five columns, each representing a quarter from Q2 2023 to Q2 2024.
**Operating Cash Flow Trend:**
* Q2 2023: $61,841
* Q3 2023: $71,654
* Q4 2023: $84,946
* Q1 2024: $99,147
* Q2 2024: $107,952
The operating cash flow has consistently increased over the five quarters, indicating a positive trend.
**Free Cash Flow Trend:**
* Q2 2023: $6,734
* Q3 2023: $20,241
* Q4 2023: $35,549
* Q1 2024: $48,778
* Q2 2024: $51,448
The free cash flow has also shown an upward trend, with a significant increase from Q2 2023 to Q2 2024.
**Significant Contributor to Free Cash Flow Trend:**
The significant contributor to the free cash flow trend is the "Principal repayments of all other finance leases" and "Principal repayments of financing obligations." These two items have consistently increased over the five quarters, contributing to the overall growth in free cash flow.
In summary, both operating cash flow and free cash flow have demonstrated a positive trend over the last 12-month period. The significant contributor to the free cash flow trend is the increase in principal repayments of all other finance leases and financing obligations.
Visual math problem answers
Another interesting problem in visual question answering is answering visual math and logic puzzles. The Llama 3.2 vision model excels at solving and answering visual math problems. Here are some examples:
The first prompt uses the following image to ask a question: “How many circles are there kangaroos in?”
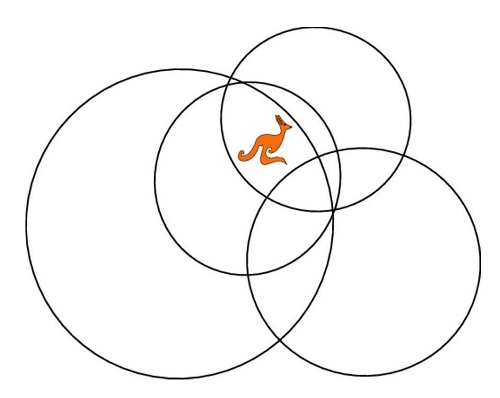
You will receive a response similar to the following:The kangaroo is inside 3 circles.
Now, use the following image to ask a question: “Which of these numbers is different from the other four numbers?”
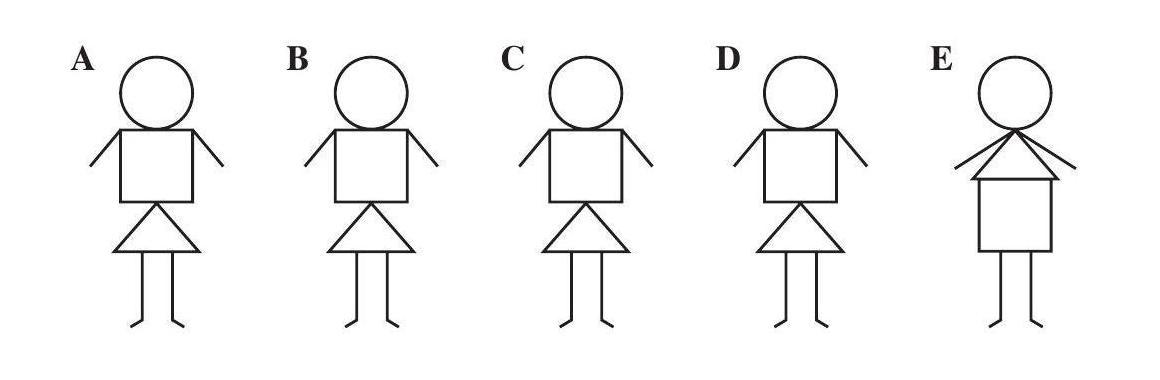
You will receive a response similar to the following:The figure labeled E is the only one with a different shape for the skirt. The other figures have triangular skirts, while figure E has a rectangular skirt.
Entity Extraction
Extracting information about products is a key use case for the retail industry. For platforms that support third-party sellers, product images are the most available resource for gathering information about products. Accurately extracting relevant information about products is therefore vital to the success of your product. In this section, we provide some example product images for clothing items and explain how to use Llama 3.2 to extract relevant information about products that can be supported in e-commerce applications.
First, use the image and prompt below “Can you extract all the information about the product in the image? Think carefully, step by step, to create a JSON file to organize all the information about the product. Consider creating a JSON file so that the extracted information can be stored in a database and further used in a retail e-commerce application. Return the JSON file as an output.”
 |
 |
For the pink dress, we get the following output:Based on the image, here is a JSON representation of the product information:
```{"product_id": "unknown","name": "Pink Floral Dress","description": "A sleeveless dress with a pink floral pattern and a pink trim at the bottom","category": "Dresses","sub_category": "Casual Dresses","color": "Pink","size": "unknown","price": "unknown","brand": "unknown","material": "unknown","features": ("Sleeveless","Floral pattern","Pink trim at the bottom"),"images": ({"url": "image_url","alt_text": "Pink Floral Dress"})}```
Please note that some information such as product_id, size, price, brand, and material are unknown as they are not visible in the image. Also, the image_url is a placeholder and should be replaced with the actual URL of the image.
For the blue cap I get this output:
Based on the image, here is a JSON representation of the product information:
```json{"product_id": "NIKE-CAP-001","name": "Nike Cap","description": "A blue baseball cap with a white Nike logo","category": "Accessories","subcategory": "Hats","brand": "Nike","color": "Blue","size": "One Size","material": "Cotton","price": 29.99,"image_url": "https://example.com/nike-cap.jpg","features": ("Adjustable strap in the back","Embroidered Nike logo on the front")}```
This JSON object includes the following fields:
* `product_id`: a unique identifier for the product* `name`: the name of the product* `description`: a brief description of the product* `category` and `subcategory`: the categories and subcategories that the product belongs to* `brand`: the brand of the product* `color`: the color of the product* `size`: the size of the product* `material`: the material that the product is made of* `price`: the price of the product* `image_url`: the URL of the product image* `features`: an array of features that describe the product
Note that this is just one possible way to represent the product information in JSON. Depending on the specific requirements of your application, you may need to add or remove fields, or use different data types for certain fields.
Caption Generation
Another important and useful feature of the Vision model is the automatic generation of captions for images. In this section, we will demonstrate caption generation with simple captions, more creative and funny captions, and marketing style captions.
Simple subtitles
For a simple caption, use this image and prompt: “Please caption this image. Be creative but respectful.”

You will receive a response similar to the following:
The image shows a young woman sitting in a dentist's chair, with a female dentist examining her teeth. The woman is wearing a bib to protect her clothes from any water or other substances that may be used during the examination. The dentist is wearing a white lab coat and a mask, and she is holding a dental mirror and a probe. The background of the image is a dental office, with various dental tools and equipment visible.
The overall atmosphere of the image is one of professionalism and care. The dentist appears to be focused on her work, and the woman seems to be relaxed and comfortable. The image suggests that the woman is receiving a routine dental checkup or cleaning, and that the dentist is taking good care of her.
Creative Captions
In the second example, I want to go for a more creative and interesting tone. I’ll use the same image and prompt. “Please write a short caption for this image. Be original, funny, and respectful. This is for sharing on social networking applications.”
You will receive a response similar to the following:
"Brace yourself for a sparkling smile, because this dentist is about to make your teeth shine brighter than a disco ball!"
List Generation
Use the following image and prompts to generate your property listing: “You’re a real estate marketing professional. Create a property description with images of the property.”

You will get output similar to the following:
**Welcome to Your Dream Home**
This stunning property boasts an open-plan living area that seamlessly blends style and functionality. The spacious living room, dining area, and kitchen are perfect for entertaining, with plenty of natural light pouring in through the large windows. The sleek, modern kitchen features high-end appliances and ample counter space, making meal prep a breeze.
The living room is a cozy retreat, with a comfortable sofa and chairs arranged around a stylish coffee table. The adjacent dining area is perfect for hosting dinner parties, with a large table that seats eight.
But the real showstopper is the stunning view of the water, which can be enjoyed from the comfort of your own home. Imagine sipping your morning coffee or enjoying a glass of wine in the evening while taking in the breathtaking scenery.
This property is the perfect blend of form and function, offering the ultimate in comfort and style. Don't miss out on this incredible opportunity to make it your own.
**Key Features:**
* Open-plan living area with kitchen, dining area, and living room* Modern kitchen with high-end appliances and ample counter space* Comfortable living room with sofa and chairs* Large dining table that seats eight* Stunning view of the water* Perfect for entertaining
**Don't miss out on this incredible opportunity. Contact us today to schedule a viewing.**
Conclusion
In this post, we introduced the diverse vision capabilities of Meta’s Llama 3.2 11B and 90B models. Llama 3.2 vision models can be used to solve multiple use cases, such as document understanding, solving mathematical and logical puzzles, extracting entities, generating captions, etc. These capabilities can improve productivity in various enterprise use cases, such as e-commerce (retail), marketing, and more.
To learn more about the capabilities and features of Llama 3.2 on Amazon Bedrock, see the release post, product page, and documentation. To learn more about using Llama 3.2 with SageMaker JumpStart, see the release post. To learn more about using basic models with SageMaker JumpStart, see the product page and documentation.
We look forward to seeing what you build with the Llama 3.2 models on AWS.
About the Author
 Dr. Natarajan Chennimalai Kumar is a Principal Solutions Architect on the Third Party Model Providers team at AWS and works closely with Meta’s Llama Partner Engineering team to make Llama models available to AWS customers. He holds a PhD from the University of Illinois at Urbana-Champaign and is based in the Bay Area, California. Outside of work, he enjoys watching shows with his kids, playing tennis and traveling with his family.
Dr. Natarajan Chennimalai Kumar is a Principal Solutions Architect on the Third Party Model Providers team at AWS and works closely with Meta’s Llama Partner Engineering team to make Llama models available to AWS customers. He holds a PhD from the University of Illinois at Urbana-Champaign and is based in the Bay Area, California. Outside of work, he enjoys watching shows with his kids, playing tennis and traveling with his family.
 Sebastian Bustillo is a Solutions Architect at AWS. He focuses on AI/ML technologies and has a deep passion for Generative AI and Compute Accelerators. At AWS, he helps customers unlock business value through Generative AI. When he’s not working, he enjoys brewing the perfect specialty coffee and spending time outdoors with his wife.
Sebastian Bustillo is a Solutions Architect at AWS. He focuses on AI/ML technologies and has a deep passion for Generative AI and Compute Accelerators. At AWS, he helps customers unlock business value through Generative AI. When he’s not working, he enjoys brewing the perfect specialty coffee and spending time outdoors with his wife.
 Marco Punio is a Senior Specialist Solutions Architect focused on generative AI strategies, applied AI solutions, and conducting research to help customers hyperscale on AWS. As a member of the AWS Third Party Model Provider Applied Science Solutions Architecture team, he serves as the Global Lead for Meta – AWS Partnerships and Technology Strategy. Based in Seattle, WA, Marco enjoys writing, reading, exercising, and building applications in his spare time.
Marco Punio is a Senior Specialist Solutions Architect focused on generative AI strategies, applied AI solutions, and conducting research to help customers hyperscale on AWS. As a member of the AWS Third Party Model Provider Applied Science Solutions Architecture team, he serves as the Global Lead for Meta – AWS Partnerships and Technology Strategy. Based in Seattle, WA, Marco enjoys writing, reading, exercising, and building applications in his spare time.
 Armando Diaz is a Solutions Architect at AWS. He focuses on generative AI, AI/ML, and data analytics. At AWS, Armando helps companies integrate cutting edge generative AI capabilities into their systems to drive innovation and competitive advantage. When not at work, he enjoys spending time with his wife and family, hiking, and traveling the world.
Armando Diaz is a Solutions Architect at AWS. He focuses on generative AI, AI/ML, and data analytics. At AWS, Armando helps companies integrate cutting edge generative AI capabilities into their systems to drive innovation and competitive advantage. When not at work, he enjoys spending time with his wife and family, hiking, and traveling the world.